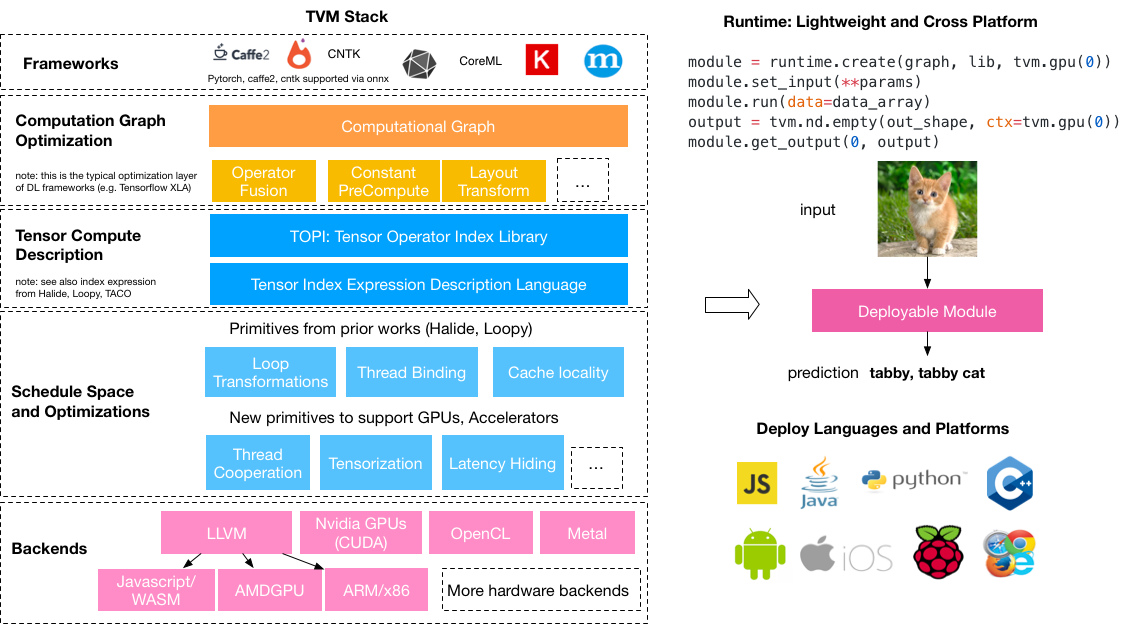
MLC-LLM is a universal solution that allows any language models to be deployed natively on a diverse set of hardware backends and native applications, plus a productive framework for everyone to further optimize model performance for their own use cases.
I am an active contributor to TVM. I have been focused on TOPI quantized operators and graph optimization in Relay IR. I contributed a full set of quantized operators for CNN on CUDA. Integrated with automatic tuning, these operators on CUDA achieved competitive performance compared with other frameworks such as cuDNN and TensorRT. Relay is a new high level intermediate representation of the computational graph. The graph optimization eliminates unnecessary computation by combining and fusing parallel branches. I strive to reduce the difficulty of deployment of deep models and bring deep learning everywhere.

As a Google Summer of Code participant in this project, I continued the ongoing detoxification of Shogun, and tackled a number of the long term design issues with the low level library. Shogun now has a clean transformer and a pipelining API using the latest C++ features. I also worked on improved exception handling, better subset data support, and some design drafts, such as a expression templates for Shogun’s linear algebra.